
랜덤 포레스트를 활용한 전남학생들의 인지능력 성취에 영향을 미치는 요인 탐색

송승훈(2024). 전남교육종단연구 제2회 학술대회 자료집.
이 연구는 랜덤 포레스트 기법을 활용하여 전남 지역 학생들의 인지능력 성취에 영향을 미치는 주요 요인을 분석한 연구 보고서입니다. 연구자는 기존의 선형 회귀 분석이나 다층 모형이 가진 복잡성과 한계를 극복하기 위해 다량의 데이터를 효과적으로 다루는 앙상블 학습 방식을 채택하였습니다.
랜덤 포레스트(Random Forest)는 결정 트리(decision tree)를 기반으로 하는 앙상블(ensemble) 학습 기법입니다. 이 방법은 전체 데이터로부터 다수의 부트스트랩(bootstrap) 표본을 생성하고, 각 표본에서 도출된 개별 결정 트리들의 결과를 결합하여 종합적으로 분석함으로써 예측 성능을 높입니다.
랜덤 포레스트 기법은 교육종단연구와 같이 변수가 많고 복잡한 데이터를 다룰 때 다음과 같은 장점을 가집니다. 첫째, 예측 변수의 수나 종류에 제한 없이 투입할 수 있으며, 수백 개의 변수 중에서도 중요도와 상호작용을 효율적으로 검증할 수 있습니다. 둘째, 전통적인 회귀분석에서 다루기 힘든 선형성이나 단일 차원성 상호작용의 한계를 극복할 수 있습니다. 특히 SHAP(SHapely Addictive exPlanations) 값 등을 활용하면 개별 예측값에 대한 각 변수의 영향력을 정교하게 배분하여 해석할 수 있습니다. 셋째, 모델 내 결정 트리 구조를 통해 효율적으로 작동하며 범용적으로 활용이 가능합니다. 반면, 산출된 결과나 모수들이 어떤 이론적 기반을 갖는지 설명하기 어려운 '블랙박스' 모형이라는 점이 가장 큰 단점입니다. 또한, 학생과 학교 효과를 구분하는 등 다층모형으로 가능한 자료의 위계성을 반영하는 데는 한계가 있습니다. 전통적인 모델은 변수와 층위가 늘어날수록 모형이 지나치게 복잡해지고 검증이 어려워지는 반면, 랜덤 포레스트는 이를 효과적으로 처리합니다. 따라서 교육종단연구처럼 예측 변수가 방대한 경우, 초기 탐색적 데이터 분석(EDA) 단계에서 중요한 변수를 걸러내거나 상호작용을 파악하기 위해 랜덤 포레스트를 활용하는 것이 매우 효과적입니다.
이 연구는 전남교육종단연구(JELS) 1~6차년도 데이터를 활용하여 초등학교 4학년부터 중학교 3학년까지의 패널1(911명)과 중학교 1학년부터 고등학교 2학년까지의 패널2(1,138명) 자료를 분석 대상으로 삼았습니다. 분석의 종속변인은 국어, 수학, 사회, 과학 교과의 성취도이며, 예측변인으로는 학생 및 학부모 설문, 학교 기본 정보 등 약 30여 개의 변수를 투입하였습니다. 분석 도구로는 파이썬(Python)의 랜덤 포레스트(RandomForestRegressor) 모델을 활용하였으며, 개별 예측값에 대한 변수별 영향력을 정교하게 배분하여 해석하기 위해 SHAP(SHapely Addictive exPlanations) 라이브러리를 사용하였습니다.
분석 결과, 모든 패널과 교과 전반에서 '수업이해도'와 '학급수업분위기'가 학업 성취에 가장 강력한 긍정적 영향을 미치는 핵심 요인으로 나타났습니다. 반면, '게임시간'은 성취도에 일관되게 부정적인 영향을 주는 것으로 확인되었습니다. 특히 중·고등학생 단계인 패널 2에서는 메타인지, 정교화, 조직화와 같은 자기주도적 학습 전략이 성취도 향상에 기여하는 반면, 단순 암기식인 '시연' 전략은 오히려 부정적인 영향을 미치는 것으로 분석되었습니다.
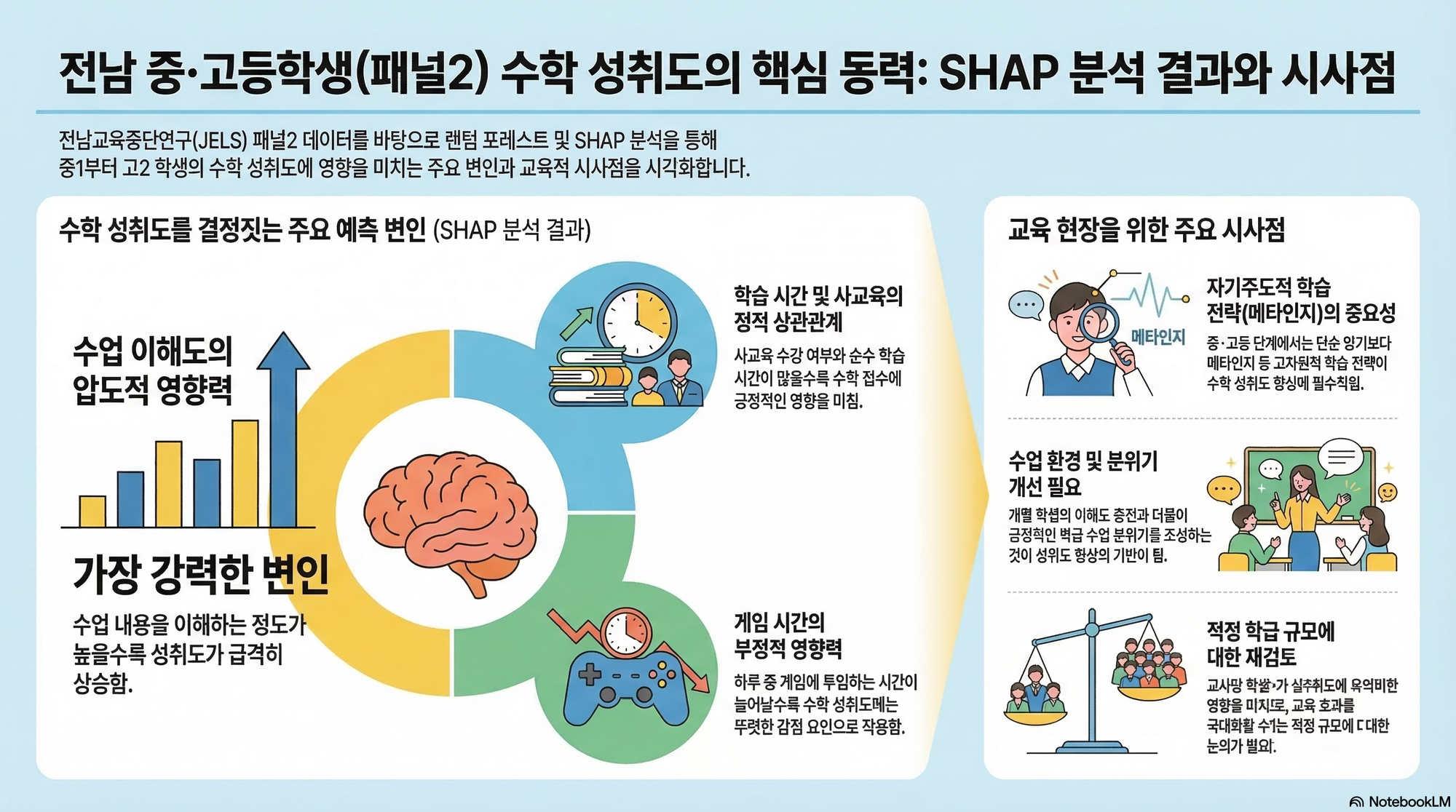
이러한 연구 결과는 전남 교육에 몇 가지 중요한 시사점을 제공합니다. 첫째, 학생들의 학업 성취를 높이기 위해서는 교실 내 수업 몰입도를 높이고 긍정적인 학습 분위기를 조성하는 현장 지원이 최우선되어야 합니다. 둘째, 상급 학교로 진학할수록 단순 암기보다는 메타인지 등 고차원적인 학습 전략을 익힐 수 있도록 돕는 교육적 개입이 필요합니다. 마지막으로, 적정 규모 학급에 대한 고민과 함께 학생들의 무분별한 게임 이용을 조절할 수 있는 생활지도 측면의 정책적 배려가 요구됩니다.



